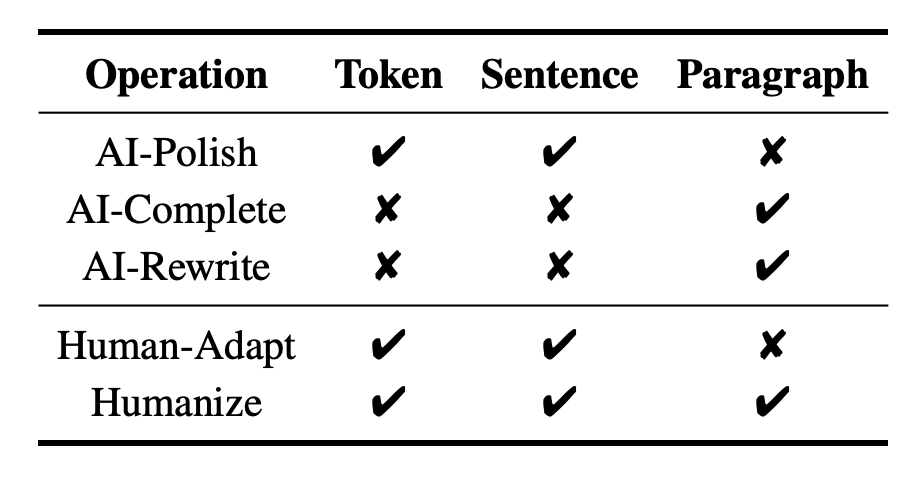
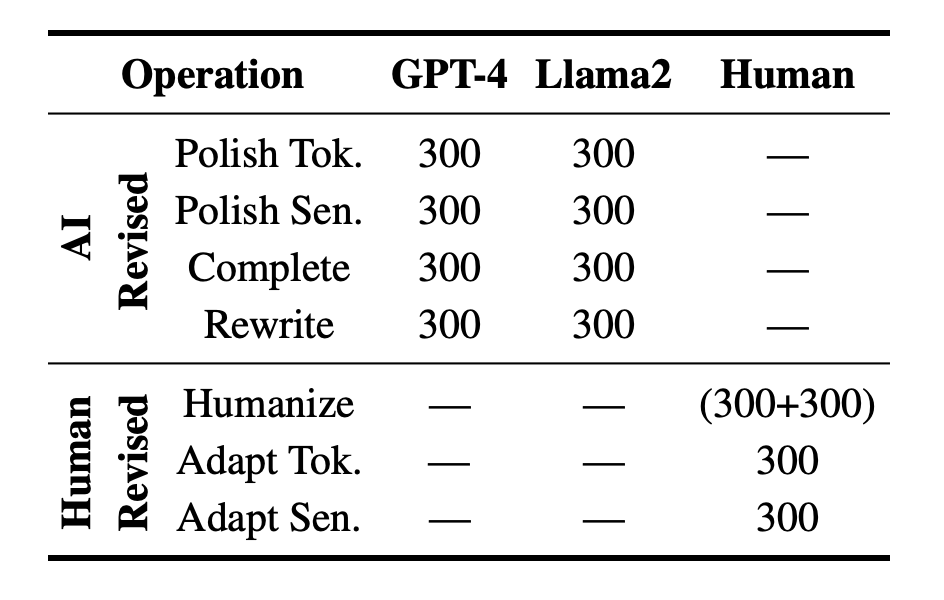
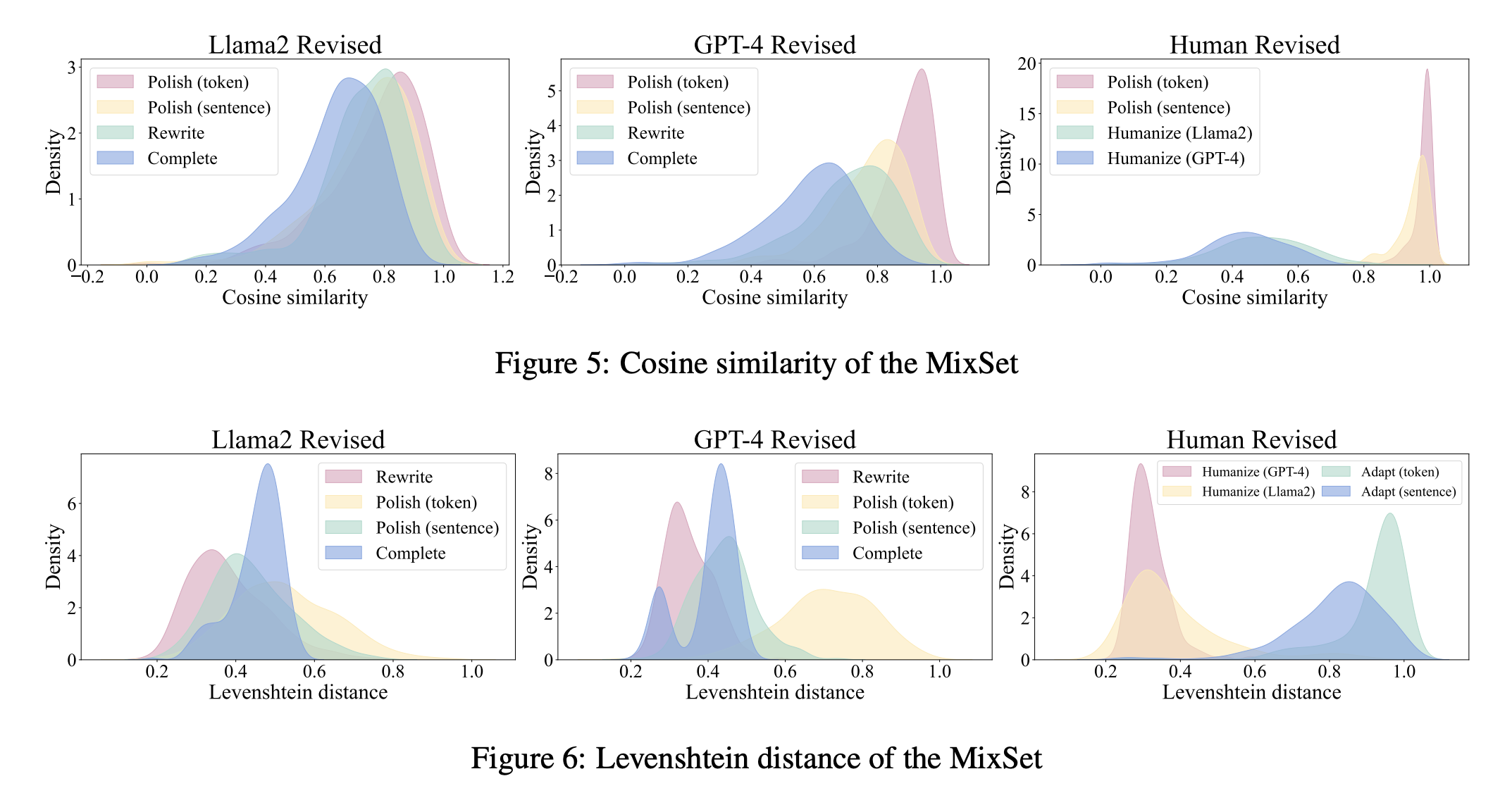
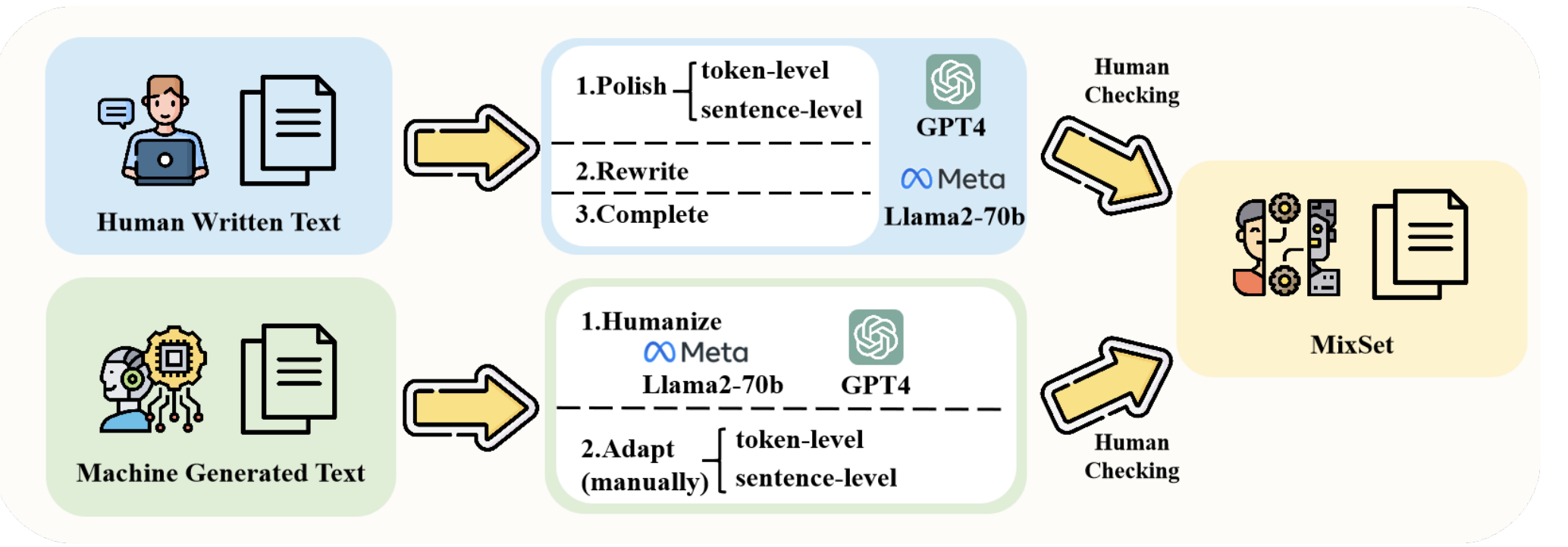
LLM-as-a-Coauthor Team




Class Number. In real-world scenarios, people often aim to detect the presence of MGT in the text (e.g., spreading fake news or propaganda, reinforcing and intensifying prejudices), and sometimes mixtext is also treated as MGT (e.g., student modified some words in MGT (i.e., mixtext) to generate homework, to avoid detection). Therefore, our experiments established two categorization systems: binary and three-class. In the binary classification, mixtext is categorized as MGT, while in the three-class classification, mixtext is treated as a separate class.
| Setting | Q 1 | Q 2 | Q 3 | Q 4 | |
|---|---|---|---|---|---|
| (a) | (b) | ||||
| Class Num. | 2-Class | 2-Class | 3-Class | 2-Class | 2-Class |
| Metric | MGT Per. | F1, AUC | F1 | AUC | F1, AUC |
| Retrained? | ✖️ | ✔️ | ✔️ | ✔️ | ✔️ |
Question 1. Based on MixSet, we evaluate current detectors to determine the classification preferences on mixtext, i.e., Does the detector tend to classify mixtext as MGT or HWT? We calculate the percentage of mixtext samples categorized to MGT in the experiment. For the DistilBERT detector and other metric-based detectors utilizing logistic regression models, we employ a training set comprising 10,000 pre-processed samples of both pure HWT and MGT. For other detectors, we use existing checkpoints or API and evaluate them in a zero-shot setting.
Question 2(a). Following Question 1, our inquiry is whether the detector can accurately classify mixtext as MGT after training on MixSet. We finetune detectors on pure HWT and MGT data and a train split set of our MixSet labeled as MGT.
Question 2(b). On the other hand, assuming that mixtext lies outside the distribution of HWT and MGT, we conduct a three-class classification task, treating mixtext as a new label. In this scenario, we adopt multi-label training for these detectors while keeping all other settings consistent.
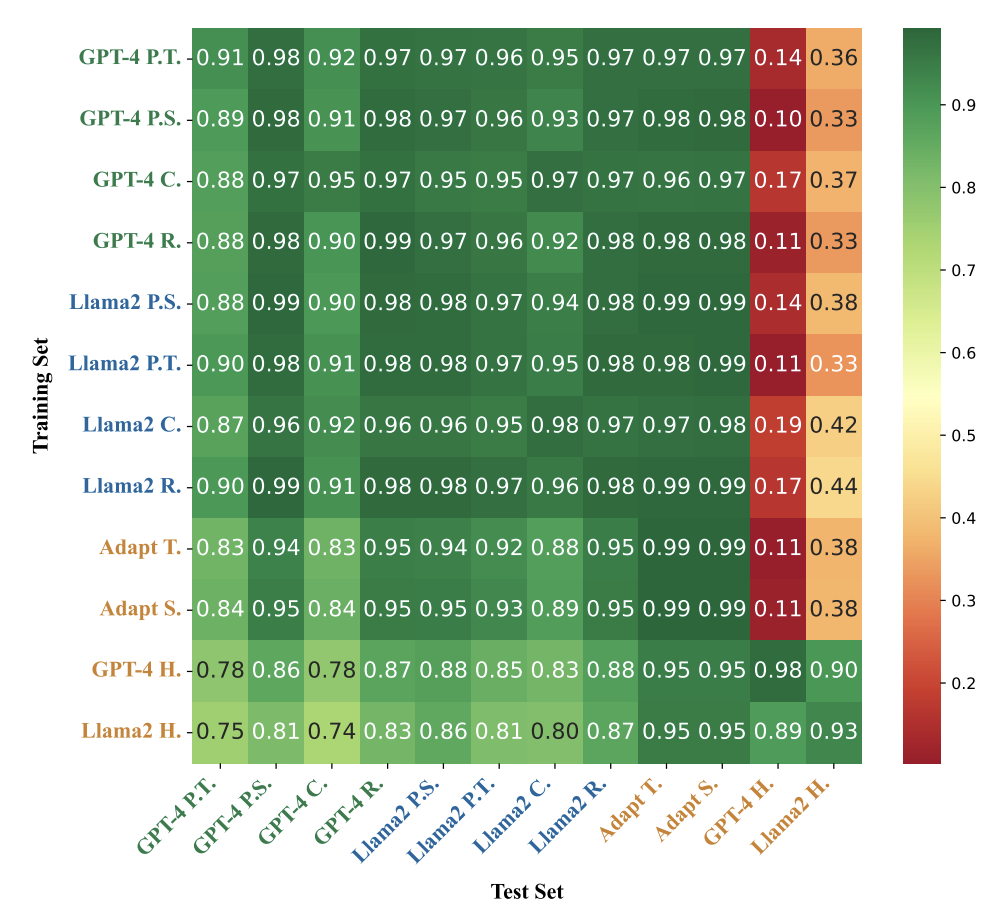
Question 3. Transfer ability is crucial for detectors, our objective is to investigate the effectiveness of transferring across different subsets of MixSet and LLMs. We establish two transfer experiments to assess whether the transferability of current detection methods is closely linked to the training dataset, referred to as operation-generalization and LLM-generalization:
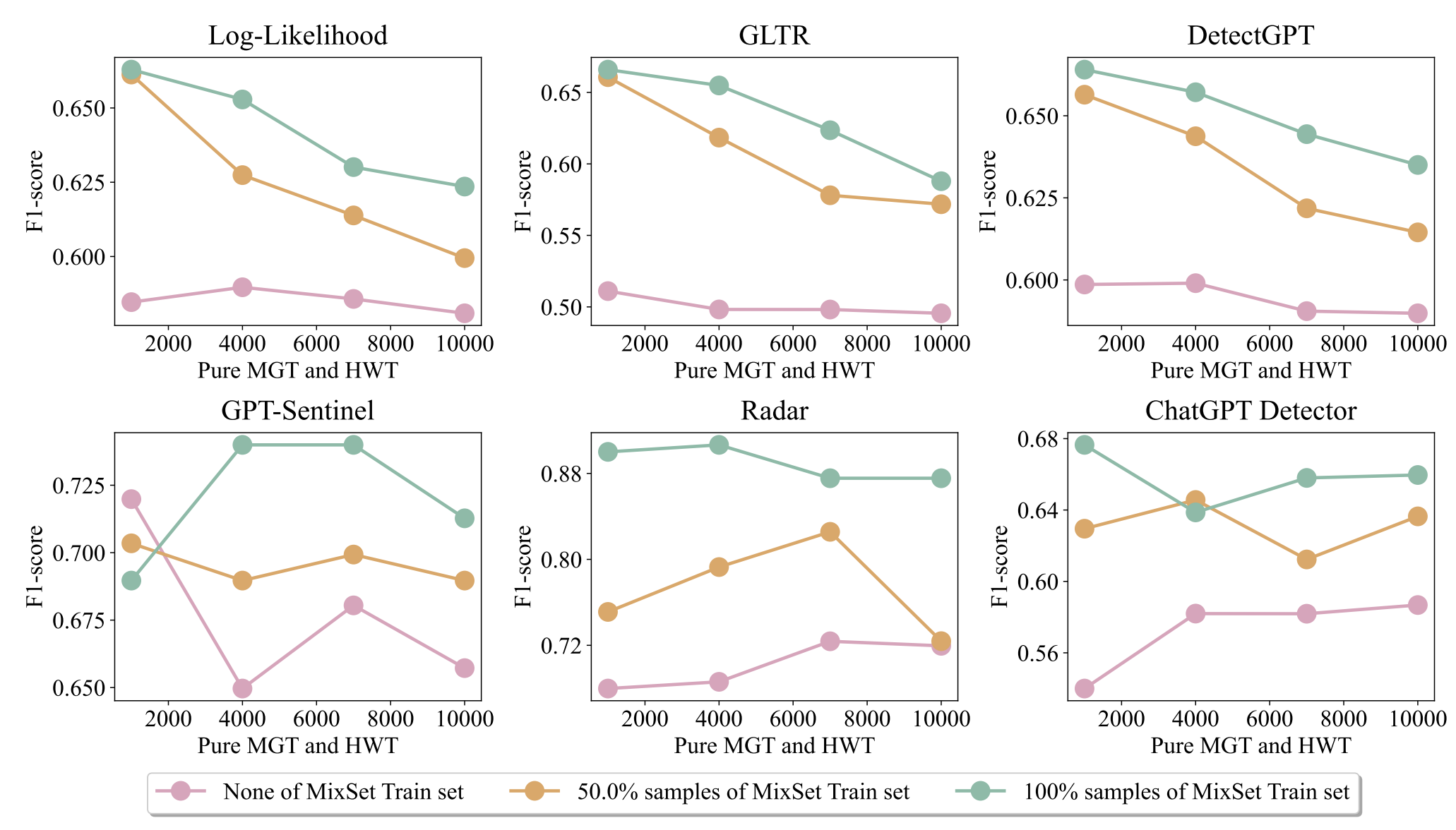
Question 4. Empirically, incorporating more training data has been shown to enhance detection capabilities and robustness for generalization. To determine the relation between detectors’ performance and the size of the training set, we follow Question 2 and use varying sizes of training sets to retrain detectors.
| Detection Method | Average | AI-Revised | Human-Revised | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Complete | Rewrite | Polish-Tok. | Polish-Sen. | Humanize | Adapt-Sen. | Adapt-Tok. | |||||||
| Llama2 | GPT-4 | Llama2 | GPT-4 | Llama2 | GPT-4 | Llama2 | GPT-4 | Llama2 | GPT-4 | ||||
| Experiment 2 (a): Binary Classification | |||||||||||||
| log-rank | 0.615 | 0.695 | 0.686 | 0.637 | 0.479 | 0.617 | 0.606 | 0.647 | 0.595 | 0.617 | 0.454 | 0.676 | 0.667 |
| log likelihood | 0.624 | 0.695 | 0.695 | 0.637 | 0.492 | 0.657 | 0.627 | 0.657 | 0.657 | 0.657 | 0.386 | 0.676 | 0.667 |
| GLTR | 0.588 | 0.686 | 0.647 | 0.606 | 0.441 | 0.574 | 0.585 | 0.637 | 0.540 | 0.617 | 0.400 | 0.657 | 0.667 |
| DetectGPT | 0.635 | 0.715 | 0.651 | 0.656 | 0.560 | 0.632 | 0.587 | 0.657 | 0.632 | 0.692 | 0.587 | 0.641 | 0.609 |
| Entropy | 0.648 | 0.690 | 0.671 | 0.681 | 0.613 | 0.681 | 0.671 | 0.681 | 0.671 | 0.623 | 0.430 | 0.681 | 0.681 |
| Openai Classifier | 0.209 | 0.171 | 0.359 | 0.031 | 0.197 | 0.145 | 0.270 | 0.247 | 0.439 | 0.247 | 0.316 | 0.000 | 0.090 |
| ChatGPT Detector | 0.660 | 0.705 | 0.696 | 0.676 | 0.583 | 0.676 | 0.647 | 0.647 | 0.594 | 0.667 | 0.615 | 0.705 | 0.705 |
| Radar | 0.876 | 0.867 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 | 0.877 |
| GPT-sentinel | 0.713 | 0.714 | 0.714 | 0.714 | 0.714 | 0.714 | 0.714 | 0.714 | 0.714 | 0.714 | 0.696 | 0.714 | 0.714 |
| Distillbert | 0.664 | 0.667 | 0.667 | 0.667 | 0.667 | 0.667 | 0.667 | 0.667 | 0.667 | 0.667 | 0.639 | 0.667 | 0.667 |
| Experiment 2 (b): Three-class Classification | |||||||||||||
| DetectGPT | 0.255 | 0.276 | 0.210 | 0.295 | 0.278 | 0.283 | 0.234 | 0.271 | 0.237 | 0.280 | 0.222 | 0.233 | 0.235 |
| ChatGPT Detector | 0.304 | 0.288 | 0.346 | 0.283 | 0.288 | 0.395 | 0.341 | 0.265 | 0.328 | 0.267 | 0.317 | 0.253 | 0.273 |
| Radar | 0.775 | 0.804 | 0.842 | 0.797 | 0.837 | 0.831 | 0.820 | 0.815 | 0.837 | 0.884 | 0.889 | 0.510 | 0.429 |
| Distillbert | 0.261 | 0.267 | 0.333 | 0.319 | 0.329 | 0.294 | 0.309 | 0.294 | 0.329 | 0.309 | 0.342 | 0.000 | 0.010 |
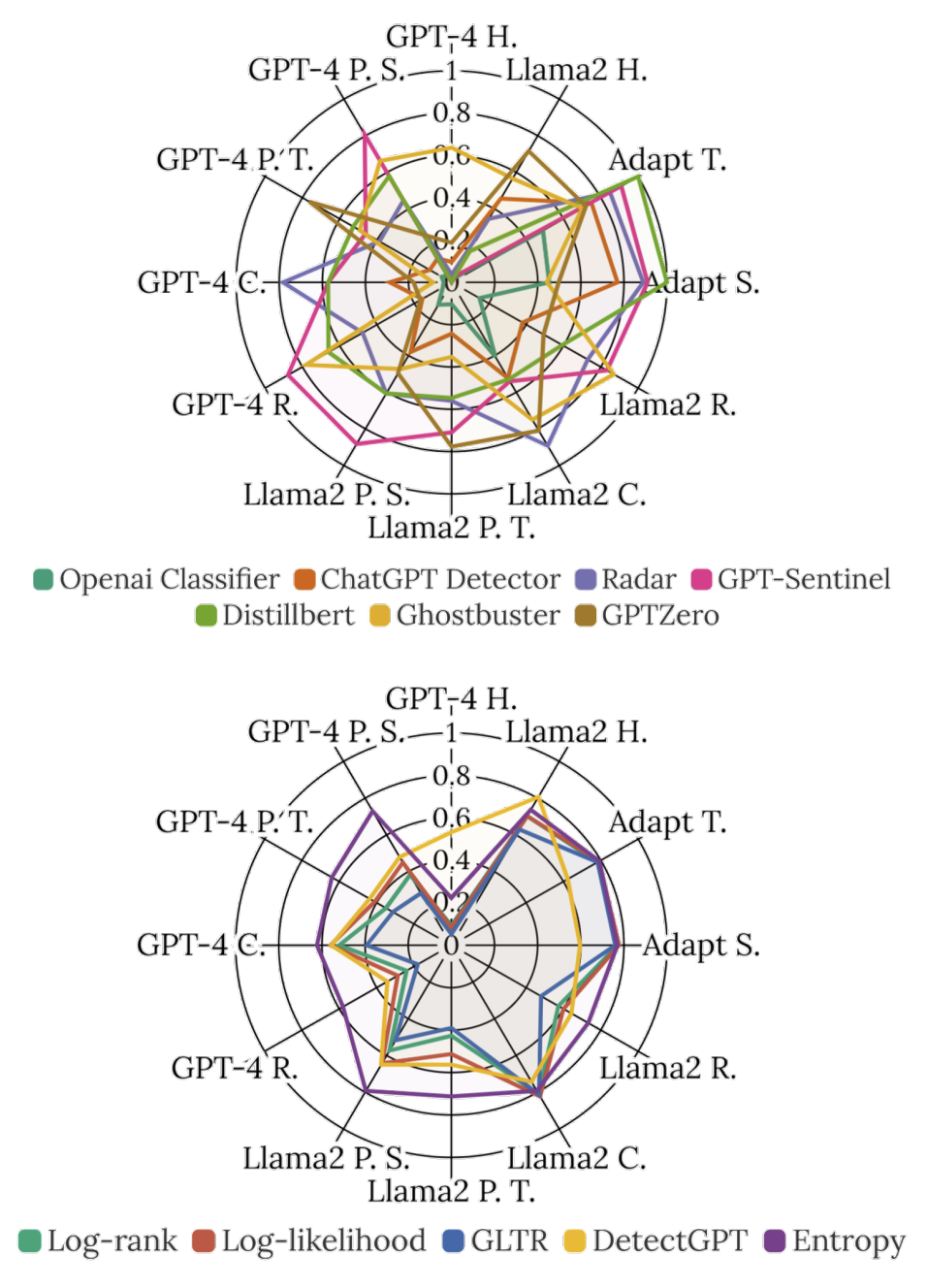
Supervised binary classification yields profound results; however, three-classes classification encounters significant challenges when applied to mixtext scenarios except Radar. Retrained model-based detectors outperform metric-based methods in both binary and three-class classification tasks. Notably, Radar ranks first in our results, achieving a significant lead over other detectors. We suppose that this superior performance can be attributed to its encoder-decoder architecture, which boasts 7 billion trainable parameters, substantially more than its counterparts. We also examined the impact of retraining on **MixSet** on MGT detection performance. There was a slight decrease in the F1 score, while the AUC metric remained largely unaffected. Notably, post-retraining, the detector acquired the capability to identify mixtext—an advancement deemed highly valuable. This ability to detect mixtext, despite a minor trade-off in F1 score for MGT detection, represents a significant step forward, suggesting a promising direction for enhancing detector versatility and applicability in varied contexts. In the three-class classification task, detectors based on LLMs, particularly the Radar detector, significantly outperformed those utilizing the BERT model. The BERT-based detectors’ performance was markedly poor, akin to random guessing, with some models even underperforming a random baseline. This stark contrast underscores the efficacy of LLMs in capturing nuanced distinctions, as demonstrated in tasks like Mixtext. The superior performance of LLM-based Radar detectors lays a solid foundation for future explorations and applications in fine-grained classification tasks.
Significant variability is observed in the transfer capabilities of three different detectors. Additionally, training on texts generated by different revised operations results in different transfer abilities for these detectors. Overall, Radar exhibits the most robust transfer capability among the four model-based detectors, achieving an overall classification accuracy exceeding 0.9, followed by GPT-sentinel, DistillBert, and finally, the ChatGPT Detector. Among various operations, ‘Humanize’ exhibits the poorest transfer performance in almost all scenarios. Additionally, other operations also experience significant declines when dealing with ‘Humanize’ mixtexts. This suggests that ‘Humanize’ falls outside the current detectors’ distribution of MGT, a gap that could be addressed by retraining on these specific cases. It is also noteworthy that texts generated by Llama2-70b demonstrate stronger transfer abilities than those generated by GPT4.
However, adding pure text samples does not yield significant improvements and may even have a negative impact on detector performance, especially for metric-based methods. This may be attributed to subtle distribution shifts between mixtext and pure text. The current detector still faces significant challenges in capturing these subtle shifts. For mixtext scenarios, a more powerful and fine-grained detection method is needed.
@inproceedings{zhang-etal-2024-llm,
title = "{LLM}-as-a-Coauthor: Can Mixed Human-Written and Machine-Generated Text Be Detected?",
author = "Zhang, Qihui and
Gao, Chujie and
Chen, Dongping and
Huang, Yue and
Huang, Yixin and
Sun, Zhenyang and
Zhang, Shilin and
Li, Weiye and
Fu, Zhengyan and
Wan, Yao and
Sun, Lichao",
year = "2024",
url = "https://aclanthology.org/2024.findings-naacl.29"}